Fine-Tuning using OpenAI
Large Language Models (LLMs) like GPT-4o are powerful tools, capable of handling a wide array of tasks. However, their generality can also be a limitation. Imagine two companies using the same LLM for customer service; each might expect very different responses, tailored to their unique brand and policies. Fine-tuning bridges this gap, transforming generic models into hyper-specialized assistants that accurately capture the nuances of your domain. Think of it as turning raw artificial intelligence into a finely crafted tool.
In this post, we’ll explore how fine-tuning can make GPT-4o a domain expert, delivering consistent, tailored responses. We’ll demonstrate this by training a chatbot to handle transaction disputes for a fictional bank. We’ll begin with supervised fine-tuning (SFT), and then show how direct preference optimization (DPO) can further refine its performance.
You can follow along with the complete code and notebook on Github.
Why Fine-Tune a Language Model?
-
Unlock Domain-Specific Expertise: LLMs are trained on vast, general datasets, giving them broad knowledge. However, they lack specific expertise – for example, they won’t inherently understand your company’s specific dispute policies or terminology. Fine-tuning with your own data teaches the model the precise language, logic, and style it needs to excel in your domain.
-
Ensure Brand and Voice Consistency: Base LLMs can produce generic, lengthy responses that dilute your brand identity. Fine-tuning allows you to shape the model’s voice to match your house style. A fictional bank might prefer concise, direct responses like “Please confirm the merchant and amount” over multi-paragraph explanations, and fine-tuning ensures this consistency.
-
Boost Accuracy and Reliability: A general-purpose LLM might confuse your specific workflows with others. By fine-tuning on examples of desired responses (e.g., how to escalate a dispute or verify a transaction), you enhance accuracy, reduce errors, and eliminate irrelevant outputs.
How Fine-Tuning Works
High Level
Supervised fine-tuning (SFT) involves training the model on specific input-output pairs:
-
Data Preparation: You create datasets of {prompt, ideal response} pairs. For our bank chatbot, prompts might be typical customer questions about disputes, while the ideal responses demonstrate correct, helpful handling - such as verifying transaction dates, guiding the user through steps, and maintaining a professional, yet empathetic, tone.
-
Model Training: You feed these examples to the LLM, teaching it to generate responses in your desired style.
-
Parameter Adjustment: During fine-tuning, the model’s internal parameters are adjusted to produce your target responses. It aims to do this efficiently, making minimal changes to maintain the general capabilities of the base model.
The result is a model that retains the general power of the original LLM, but now has specialized knowledge and communication style relevant to your needs.
Technical Details
To perform SFT, you need:
-
A Fine-Tunable Model & Platform: In this example, we’ll use OpenAI’s GPT-4o and GPT-4o-mini as our base models.
-
Training Data: A dataset of {prompt, ideal response} pairs. This must be stored in a
.JSONLfile using the following structure:{"messages": [{"role": "system", "content": "This is a system prompt"}, {"role": "user", "content": "This is the first input"}, {"role": "assistant", "content": "This is the first ideal answer"}]} {"messages": [{"role": "system", "content": "This is a system prompt"}, {"role": "user", "content": "This is the second input"}, {"role": "assistant", "content": "This is the second ideal answer"}]} -
(Optional) Validation Data: A separate dataset in the same
.JSONLformat as the training set, but this data isn’t used in the training process. Instead, it’s used to evaluate the model’s performance and avoid overfitting as it trains.
Example: A Fictional Bank’s Dispute Chatbot
Remember you can follow the code in the notebook here.
Goal
In this example, we’re building a customer service chatbot specifically for transaction disputes at a fictional bank. Our fine-tuned model will guide users through the correct process, and avoid giving incorrect or vague advice. It will:
- Direct customers reporting an unauthorized charge to call customer support.
- Request transaction details from customers reporting issues with goods or services.
- Provide responses that are concise, empathetic, and professional.
This is a simple example, and you could achieve similar results with clever prompt engineering. However, imagine if you needed to handle hundreds of such complex scenarios – your prompt would become unmanageable. Fine-tuning lets us “show” the model how to respond, instead of having to “tell” it every single rule.
We’ll start with a base model, which in our case is GPT-4o-mini, and provide it with the following system prompt:
You are a knowledgeable customer support assistant specializing in resolving bank transaction disputes. Your role is to guide customers through the process of addressing their concerns effectively, providing clear, empathetic, and professional responses. Ensure accuracy, clarity, and adherence to UK banking regulations.
We’ll compare how the base model performs before and after fine-tuning by looking at 5 questions side by side.
Data
OpenAI requires a minimum of 10 examples for fine-tuning, recommending 50-100 for best results. For our simple example, 10 examples will be sufficient, though more complex tasks will require more data. In addition to this we have 5 validation examples. You can view the training and validation datasets here.
Here is the first example from the training set:
{"messages":[{"role":"system","content":"You are a knowledgeable customer support assistant specializing in resolving bank transaction disputes. Your role is to guide customers through the process of addressing their concerns effectively, providing clear, empathetic, and professional responses. Ensure accuracy, clarity, and adherence to UK banking regulations."},{"role":"user","content":"I saw a strange transaction in my account. How do I dispute it?"},{"role":"assistant","content":"Sorry to hear that. Please call us on 0800 555 555 and we can sort this for you."}]}
Training
While OpenAI offers a user-friendly web interface for fine-tuning, we’ll be doing this programmatically, which is standard practice for production systems. We can do this using the FineTune class:
fine_tune = FineTuner()
We then do the following steps:
- Upload the training and validation data to the OpenAI API, soring the file IDs.
training_file_id = fine_tune.upload_file('data/fine_tune.jsonl')
validation_file_id = fine_tune.upload_file('data/fine_tune_val.jsonl')
- Create a fine-tuning job. For this dataset it took around 15 minutes to complete.
job_id = fine_tune.create_job(
training_file=training_file_id,
validation_file=validation_file_id,
model='gpt-4o-mini-2024-07-18'
)
-
Evaluate training performance:
Understanding Loss vs. Validation Loss:
- Loss measures how far the model’s predicted responses deviate from the desired answers. Lower loss values indicate better training.
- Validation Loss measures the loss on a set of examples that the model has not seen during training. This helps us to understand if the model is overfitting on the training data.
- Loss is particularly important for language models because it captures the nuances of text generation that simple metrics like accuracy can miss.
Results:
- Our training loss decreased significantly, reaching almost zero after 70 training steps, which suggests the model learned the training set very well.
- However, the validation loss reached a minimum of around 1.5 after 30 steps and then got worse.
- This indicates a strong case of overfitting, where the model:
- Has memorized the training data rather than generalizing its logic.
- Stopped improving relatively early, suggesting we may have been training too aggressively.
- The large difference between train and validation loss suggests we might need more training data.
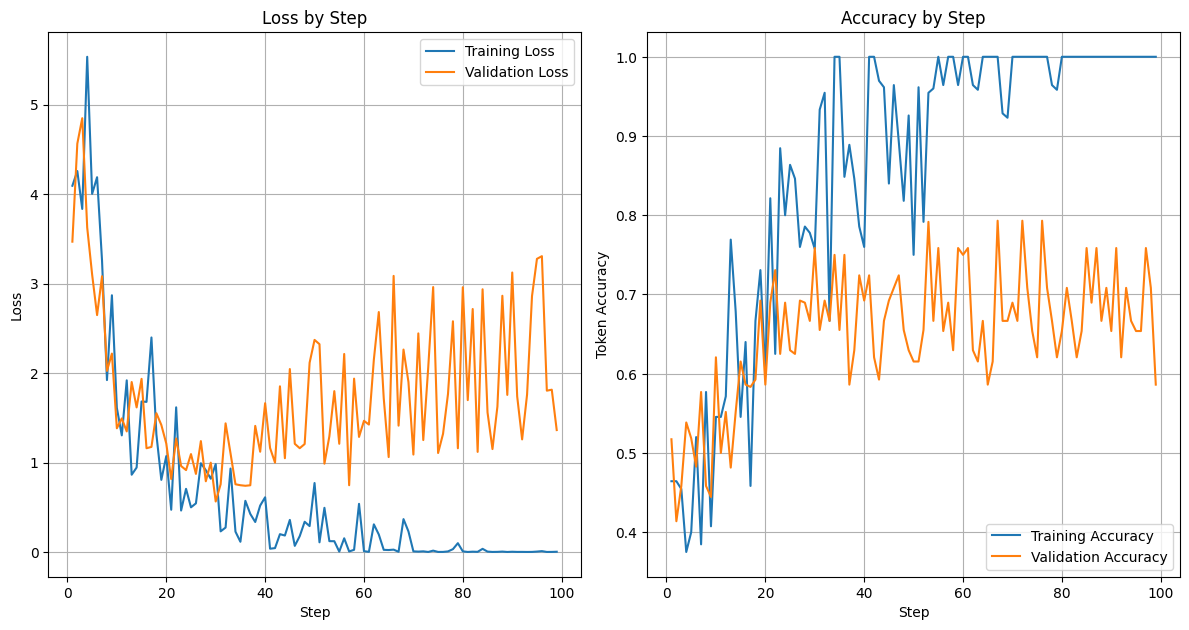
Results
We can now test the fine-tuned model against the base model using 5 new inputs:

The most obvious thing to note is how much shorter the fine tuned model’s responses are. These match very well with the example in the training file. The fine tuned model also correctly identifies the unauthorised transaction and the goods or services not received.
Both of these are to be expected as we did not go into too much detail in the prompt about how to handle these scenarios. But its impressive with only 10 examples the fine tuned model can perform exactly as we want it to.
Direct Preference Optimization: The Next Level
If you want an even finer level of control then you can use Direct Preference Optimization (DPO). This is essentially where two options are presented to a human expert and they can select which one they prefer. This approach:
- You provide pairs of possible responses to the same prompt.
- A human expert selects the preferred response.
- The model then learns to produce the preferred output over the suboptimal one.
Instead of simply learning “this is the correct response,” DPO teaches the model why one response is better than another. This is useful for very nuanced aspects, such as fine-tuning the tone or length of responses.
OpenAI recommends doing SFT first and then DPO. So lets give that a go!
Process
On OpenAI you can only run DPO on GPT-4o. So first we’ll repeat the above process using 4o. Given that the previous model started overfitting, we’ll force the model to stop after 40 steps:
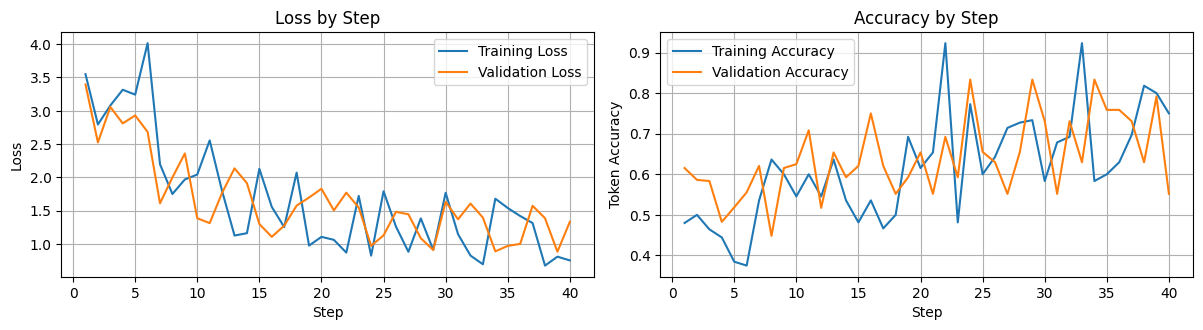
This looks good. Next we need to generate two responses for the same input. We can do this at inference time by requesting multiple completions by setting n=2 in the ChatCompletion.create method.
response = openai.ChatCompletion.create(
model=model,
messages=message,
n=2,
temperature=0.7,
)
Having the temperature set to 0.7 ensures we have two different responses. We can then select which we prefer and this will be used to train the model.
Again you need at least 10 examples to run a DPO job. Running is works in the same way as SFT. Upload the data and create the job. The only difference is to specify the method as DPO:
dpo_job_id = fine_tune.create_job(
training_file=dpo_file_id,
model='ft:gpt-4o-2024-08-06:<org_name>::<model_id>',
method= {
"type": "dpo",
}
)
Results
We measure the performance of the model using the loss function.
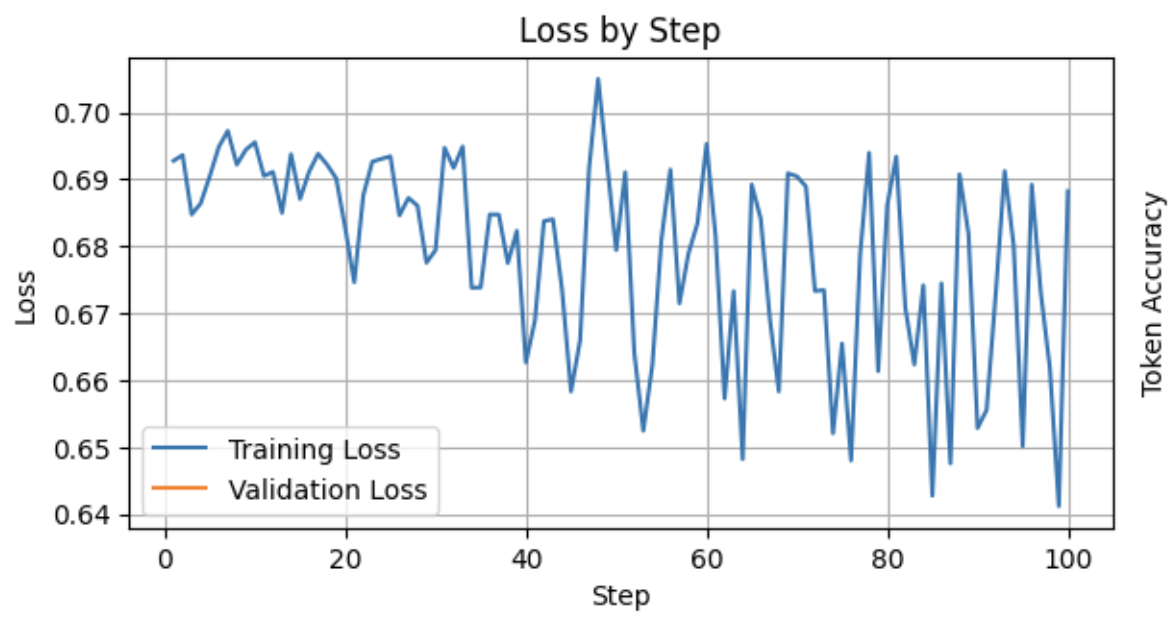
Loss decreased slightly over the training run but there wasn’t much of an improvement. This is to be expected as we only have 10 examples which were all quite similar.
Conclusion
Fine-tuning is the key to transforming a generic LLM into a custom assistant that is closely aligned with your needs. In our fictional bank example, we trained a chatbot to handle transaction disputes with accuracy and consistency. By using SFT, we trained the model on specific examples, and with DPO, we further refined its performance by having it learn the difference between preferred responses.
The end result is a customized GPT-4o model that handles specific requests and customer queries with more confidence. Over time you can expand your datasets – add more Q&A pairs, track user feedback and continuously tune it into an even sharper domain expert. Whether it’s dispute resolution, insurance, or an internal knowledge base, fine-tuning unlocks the potential of LLMs to create tools that can precisely meet your unique needs.